

| Dr. Marco Antonio Castro Liera | MSC. Iliana Castro Liera |
Maestría en Sistemas Computacionales
División de Estudios de Posgrado e Investigación
Tecnológico Nacional de México
Instituto Tecnológico de La Paz
El aprendizaje automático (machine learning) es un área de la Inteligencia Artificial en la que se trata de desarrollar sistemas que mejoran su desempeño a partir del análisis de conjuntos de datos.
A diferencia de la forma tradicional de desarrollar aplicaciones computacionales, en la que un equipo de programadores debe escribir explícitamente el conjunto de reglas que una computadora seguirá para resolver un problema, el enfoque de aprendizaje automático confía en la generación de un modelo que, a partir de una serie de ejemplos, reproduzca de manera automática el comportamiento del sistema deseado.
Para poder resolver un problema mediante esta técnica, debe contarse con tres elementos principales (Mitchell, 1997):
- Definición del problema: Debe describirse con mucha precisión el problema que se trata de resolver, de tal suerte que se pueda demostrar formalmente si se ha encontrado una solución al mismo.
- Medida de desempeño: Debe contarse con una forma de cuantificar la calidad de la salida del sistema, esto es, debe ser posible obtener un número que nos diga que tan buena es la solución al problema obtenida por un modelo en particular. Esta medida se utilizará para poder aplicar un método de optimización que permita ir mejorando el desempeño del modelo.
- Experiencia: Se refiere a un conjunto de datos que servirán como ejemplos para entrenar el modelo a desarrollar.
Por ejemplo, si el problema que queremos resolver es el de jugar ajedrez, deberemos poder caracterizar una posición ganada o de tablas, así como el conjunto de reglas básicas de posición inicial y movimientos permitidos. En ese caso, el desempeño puede medirse como el porcentaje de partidas ganadas, empatadas y perdidas, o mediante un estadístico como el ELO (que se usa para clasificar a los jugadores humanos). La experiencia podrá ser un conjunto de partidas digitalizadas entre maestros de ajedrez que nos permitan generar un modelo que recomiende la mejor jugada posible para una posición en el tablero.
Entrenamiento
El entrenamiento de un modelo de aprendizaje automático se refiere al ajuste de los parámetros del modelo para que la salida del mismo se asemeje lo más posible a la deseada. Para que el entrenamiento sea exitoso se requiere de una cantidad considerable de ejemplos en formato digital para ser procesados por un algoritmo de optimización que normalmente se ejecuta en una computadora.
El gran éxito que han tenido hoy en día los modelos de aprendizaje automático se deben en gran medida a dos factores, por un lado la creciente capacidad de procesamiento de las computadoras actuales (por ejemplo, un simple teléfono celular de hoy en día es más potente que la computadora que controlaba la misión del Apolo XI) y por otra parte la gran cantidad de datos disponibles en formato digital.
Casi todos los sistemas actuales se controlan mediante computadoras y van generando cantidades enormes de información explotable mediante técnicas de aprendizaje automático, cuando hacemos compras, usamos nuestros dispositivos móviles, usamos nuestros automóviles o llevamos a cabo un proceso productivo, vamos generando información transaccional que puede agregarse en grandes bases de datos que permiten crear modelos para el análisis y mejora de muchos procesos.
Entrenamiento supervisado
En este caso, el conjunto de ejemplos básicamente se trata de un archivo con información en columnas de entrada y una columna con la salida deseada. A los valores de salida se les conoce como etiquetas y a los valores de entrada de cada ejemplo del conjunto de datos se les conoce como patrones. El proceso del entrenamiento supervisado ajusta los parámetros y la estructura (hiper-parámetros) de un modelo para que la salida que se genera para cada patrón de entrada se parezca lo más posible a la contenida en el conjunto de datos de entrenamiento. Una vez entrenado el modelo, es posible alimentarlo con nuevos patrones y obtener las salidas correspondientes, como se muestra en la figura 1.

Aprendizaje no supervisado.
En este caso no se cuenta en el conjunto de datos de entrada con una salida deseada (los datos no están etiquetados). Las técnicas más usuales que se aplican a este tipo de problemas se conocen como análisis de grupos (clustering) y tratan de identificar conjuntos de datos que sean parecidos entre sí. Una aplicación común de este tipo de técnicas es la de encontrar patrones de consumo en la clientela de tiendas de autoservicio.
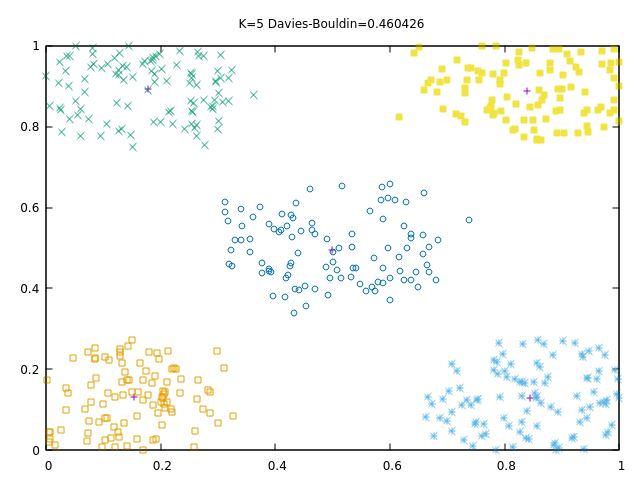
Existen métricas que permiten determinar la calidad de un agrupamiento utilizando la distancia promedio entre los elementos del mismo grupo y entre los centroides de grupos diferentes, una de las más populares se conoce como índice de Davies-Bouldin, la figura 2 muestra un ejemplo de agrupamiento.
Aprendizaje por refuerzo
Este es un enfoque inspirado en las teorías conductistas que permite al sistema aprender desde cero, mediante castigos y recompensas mientras se le van presentando nuevos datos. En este caso se utiliza una medida de desempeño que permite castigar o premiar la salida del modelo incluso cuando este se encuentra en producción.
Automatización del proceso
Por último, cabe recalcar que una de las grandes ventajas de este enfoque es que permite la automatización del proceso de aprendizaje, esto quiere decir que el sistema puede seguir mejorando su desempeño inclusive cuando ya se ha puesto en funcionamiento, como se muestra en la figura 3, por ejemplo, los sistemas que filtran el correo electrónico permiten al usuario marcar manualmente correos como válidos o no deseados y ajustan los parámetros del modelo para hacer una mejor clasificación automática en el futuro (A. Géron, 2019).

Presentación: El aprendizaje automático es un área de la Inteligencia Artificial en la que se desarrollan sistemas que mejoran su desempeño a partir del análisis de conjuntos de datos. Actualmente esta área ha ganado gran popularidad debido a los impresionantes avances que se han obtenido dentro de la misma.
Referencias.
A.Géron. (2019). Hands-on machine learning with Scikit-Learn, Keras and TensorFlow: concepts, tools, and techniques to build intelligent systems. In O’Reilly Media (2nd ed.). Oreilly & Associates Inc.
Mitchell, T. M. (1997). Machine Learning (1st ed.). McGraw-Hill Science/Engineering/Math.